 ふと思い立ち、Virtual PC 2004を使ってみる事にしました。このソフトは、Windows上に仮想マシンをエミュレートし、1台のPCであたかも複数のPCが動いてるような感じに出来るソフトです。しかも無料。
ふと思い立ち、Virtual PC 2004を使ってみる事にしました。このソフトは、Windows上に仮想マシンをエミュレートし、1台のPCであたかも複数のPCが動いてるような感じに出来るソフトです。しかも無料。
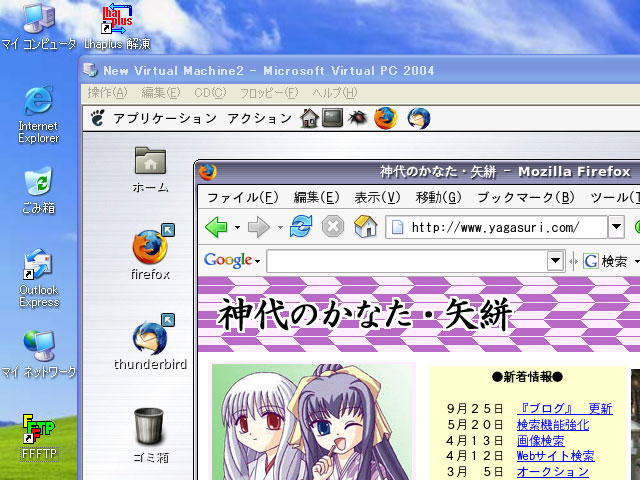
まずはVirtualPCをインストール。普通に「次へ」「次へ」と押していくだけでセットアップ完了します。次にOSを入れます。今回選んだのはVine Linux 3.2です。理由は何となく。前に自宅サーバ作った時にはRedHatLinux使ったんだけどね。こちらも何も考えずボタンを押していくだけでインストール開始します。「モニタ不明」と出て、ちょっと気になったけど、そのままで動いたので良し。
楽チンですね。XWindowはディフォのGnomeで起動。全く問題なく動きます。ネットワークも自動検出。ただ入ってたのがMozillaだったんで、FireFOXに載せ換え。メールソフトもThunderBirdに。
メモリ512Mbyteしか載ってなくて不安でしたが、そんなに重くならない。ただ、データのやり取りが面倒かな。
さて久しぶりに、サーバ系のソフトを色々試してみようかね。