 AIを使ってなんかサービス作りたいなとずっと考えてました。
AIを使ってなんかサービス作りたいなとずっと考えてました。
まだ具体的なアイデアはないんだけど、ひとまずサーバ上でLLMを動かすことにしました。
初期設定
Ollamaをインストール・起動させます。ちなみにサーバはRocky Linuxです。
$ curl -fsSL https://ollama.com/install.sh | sudo bash $ sudo systemctl enable ollama $ sudo systemctl start ollama
テストなのでLLMは軽いGemma3:1Bにしました。サイズは約800MBです。
$ ollama pull gemma3:1b $ ollama run gemma3:1b
これでもう動くようになりました。
シェルから実行
すでにサーバとして機能しているのでcurlで実行。
$ curl http://localhost:11434/api/generate -d '{
"model": "gemma3:1b",
"prompt": "こんにちは",
"stream": false
}'
実行結果。ちゃんと生成されてるね。
{
"model": "gemma3:1b",
"created_at": "2025-11-13T17:26:31.152516263Z",
"response": "こんにちは!何かお手伝いできますか? 😊 \n\n何か質問はありますか? それとも、何か話したいことなどありますか?\n",
"done": true,
"done_reason": "stop",
"context": [(長いので省略)],
"total_duration": 2328612666,
"load_duration": 415811149,
"prompt_eval_count": 10,
"prompt_eval_duration": 72922878,
"eval_count": 31,
"eval_duration": 1786284074
}
jsonの意味は以下がわかれば良いか。
response:生成テキスト
context:会話を継続する場合に使う値
total_duration:リクエスト全体にかかった時間(2.3秒)
eval_count:モデルが生成したトークン数
Webサービス作成
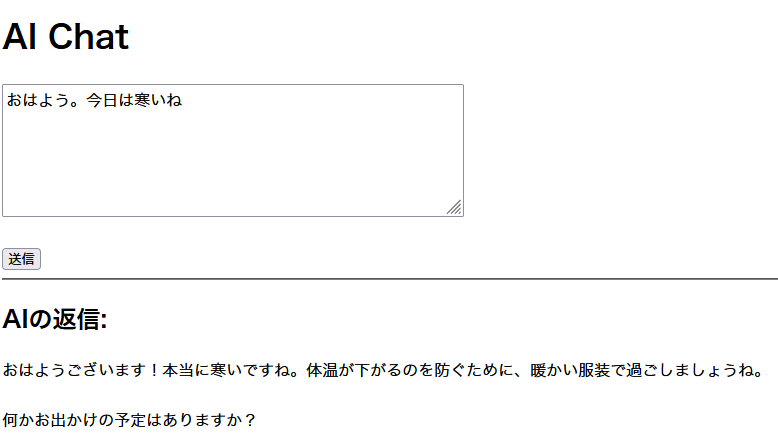 入力テキストをcurlでOllamaに渡すだけのシンプルなフォームを作成しました。
入力テキストをcurlでOllamaに渡すだけのシンプルなフォームを作成しました。
しょぼいけどAIを使ったWebサービス完成です。
ちなみにサーバースペックは3Core, 2GBでGPUなしです。こんなスペックでも動くんだね。
なお入力テキストの長さによって生成時間はかなり変わります。そしてGemma3:1Bは長いと生成テキストが壊れることがあります(汗)
その他の設定
今は必要ないけど、WebサーバとAIサーバは分けたほうが良い気がするので設定。
AIサーバにてFirewalldでポートを解放しつつIPアドレス制限します。
$ sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="(IPアドレス)" port port="11434" protocol="tcp" accept' --permanent $ sudo firewall-cmd --add-rich-rule='rule family="ipv4" port port="11434" protocol="tcp" drop' --permanent $ sudo firewall-cmd --reload
Ollamaの外部アクセス許可します。
$ sudo systemctl edit ollama 以下を追加 [Service] Environment="OLLAMA_HOST=0.0.0.0:11434"
反映。
$ sudo systemctl daemon-reload # sudo systemctl restart ollama
AIサーバに関しては余ったPC使って自宅サーバ立ち上げるのもいいかなと思ってます。GPU載ってるし。
まとめ
思ったより簡単にAIサービス動かせました。Ollamaのお陰です。
あとはアイデアだね。

コメント