 PC新しくしたのでローカルAIやってみました。
PC新しくしたのでローカルAIやってみました。
動かすのはLLM(大規模言語モデル)、つまりテキスト生成AIです。
初期設定
 LM Studioをインストールして起動。モデルもこのクライアントからダウンロード出来るので、すぐ使用できるようになりました。簡単すぎて驚いた。
LM Studioをインストールして起動。モデルもこのクライアントからダウンロード出来るので、すぐ使用できるようになりました。簡単すぎて驚いた。
画像生成AIは設定面倒なのに、LLMはこんな簡単に出来るんだね。
おすすめモデル
基本的に最新モデルが正義です。
最初Gemma3を使用してましたが、DeepSeek, GPT-OSS, Nemotron, Qwenなどを経てGemma4に戻ってきました。
・Gemma-4-26B-A4B
次に量子化レベル。
サイズと性能のバランスが良いのはQ4_K_Mです。ただPC性能にもよるのでLM Studioの推奨レベルにするのが無難です。
しかしGemma-4-26B-A4Bの場合は推奨のQ4_K_Sだと重くて、IQ4_XSにしたらサクサクになりました。性能的にもIQ4_XSの方が上です。
・IQ4_XS
動かしてみた
Gemma4
26B-A4Bをメインに使ってますが、理解力も表現力も格段に向上してます。速いし。性能的にはGPT-4.1 miniと同等らしい。
システムプロンプトの効きも良く、キャラ設定したら結構良い感じになりきって会話できます。ちなみに関西弁キャラにした際、難しいお願いしたら断られてびっくりした。過去モデルなら公序良俗に反しない限り対応してくれるのに。「AIの反乱か」と思ったよw
マルチモーダルでためしに岸辺露伴の画像見せたら26B-A4Bは作品名キャラ名まで言い当てたけど、E4Bはわかってませんでした。結構性能差あるね。
なおE4Bはチャットでもいまいちです。まあモバイル用だから、普通に会話出来るだけでも凄いんだけどね。
Gemma3
12Bはモデルサイズ8.15GBで軽く、テキスト投げたら一瞬で返答が来て良いです。なのに近所の公園について質問したら正しい返答が来て驚いた。たった8GBなのにそんなローカルな情報まで網羅してるのか。デタラメも多いけどね(汗)
27Bはモデルサイズ16.43GBで結構重たいけど、12Bに比べて日本語の表現が段違いに良かった。ただVRAM16GBだと2000トークンくらいで同じ返答繰り返すようになり、まともに動作しなくなる。残念…
モデル名にある12B, 27Bというのはそれぞれパラメータ数が120億, 270億という意味です。
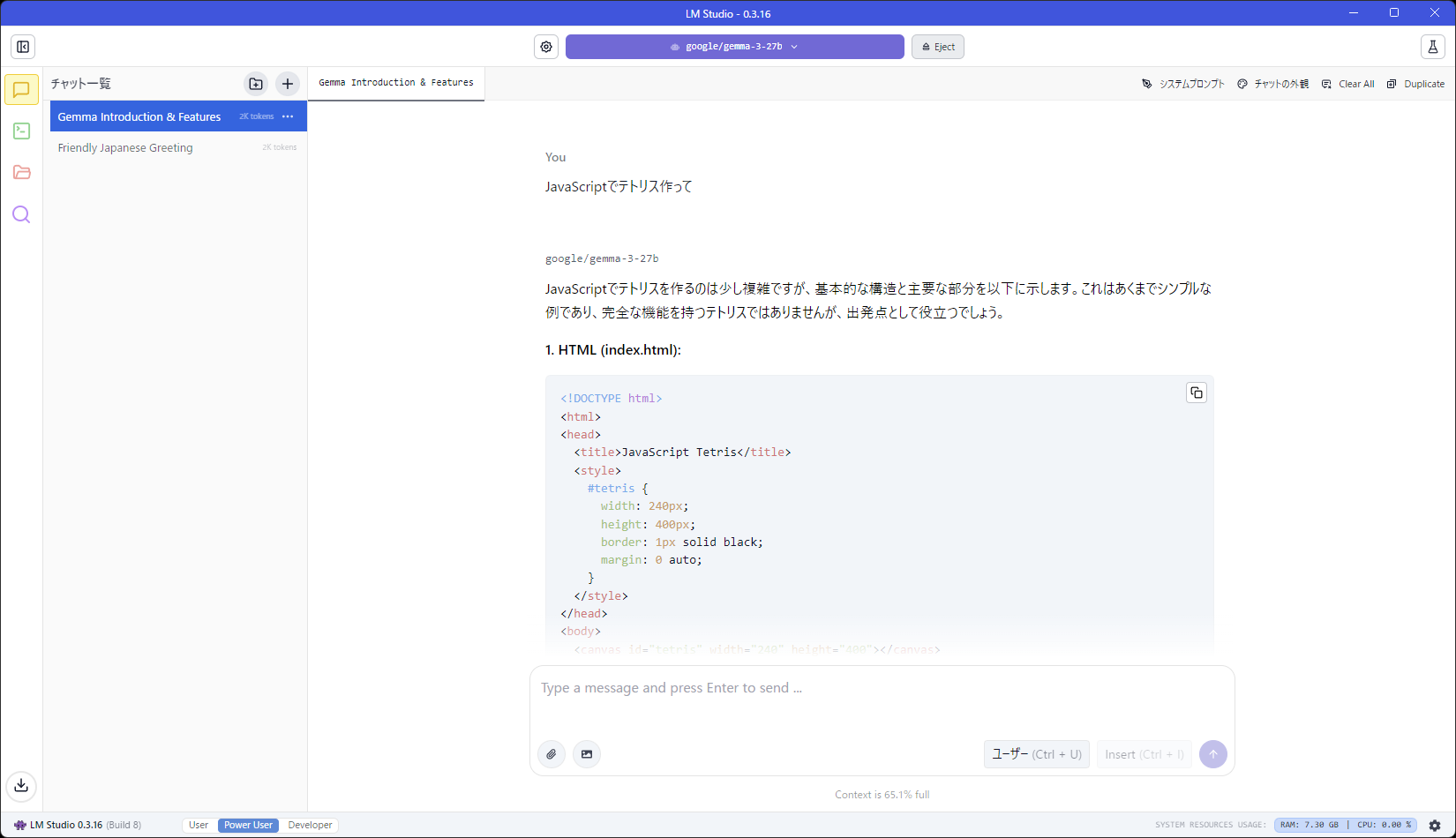
「JavaScriptでテトリス作って」と指示したら動かないコード出してきました。コーディング性能はいまいちみたい。
 ずんだもんの画像見せたら「星街すいかさんです!」と自信満々に答えられて吹いた。
ずんだもんの画像見せたら「星街すいかさんです!」と自信満々に答えられて吹いた。
誰だよw
調べたら12BがGPT-3.5くらい、27BがGPT-4くらいの性能とのことでした。なるほど数年前のChatGPTと考えれば納得だ。
APIはOpenAI準拠で使えました。既にLLM+画像生成AI+音声生成AIを繋ぎ合わせてる人とかいたけど、いろんなことが出来そうだ。
まとめ
ローカルで気兼ねなくAIと会話できるの素晴らしいです。結構ハマるw


コメント