 Irodori-TTSという、感情表現豊かな音声生成モデルを知りました。日本語が綺麗で文脈からある程度感情を類推して喋ってくれる。これは面白い。
Irodori-TTSという、感情表現豊かな音声生成モデルを知りました。日本語が綺麗で文脈からある程度感情を類推して喋ってくれる。これは面白い。
せっかくなのでLLMと組み合わせてAIとの音声チャットが出来ないかと調べてみました。結局うちの環境ぴったしな情報は無かったので、AIに聞きながら構築しました。
セットアップ環境
環境
PC:RAM32GB, VRAM16GB
OS:Windows11
使用ツール
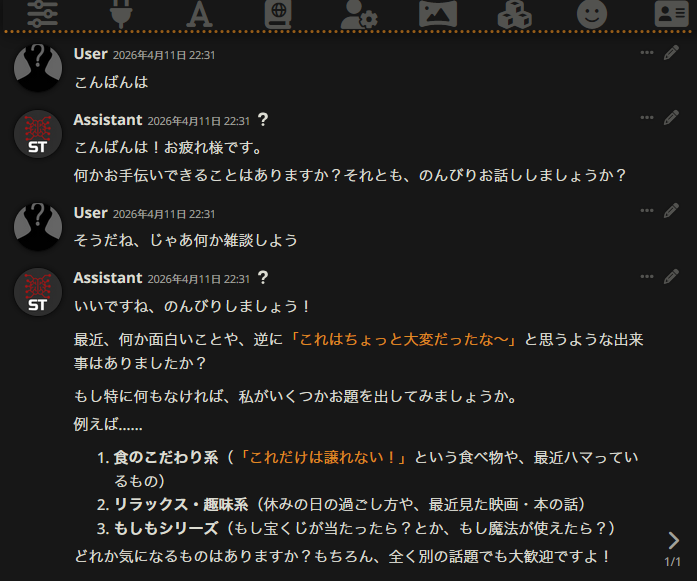
AI:LM Studio(Gemma4-26B-A4B)
音声:Irodori-TTS(500M-v2)→ 500M-v3
UI:SillyTavern
※Irodori-TTSがv3になっても以降の処理は問題なく動きました。
LM Studio
 インストール方法などは省略。API利用許可だけ出します。
インストール方法などは省略。API利用許可だけ出します。
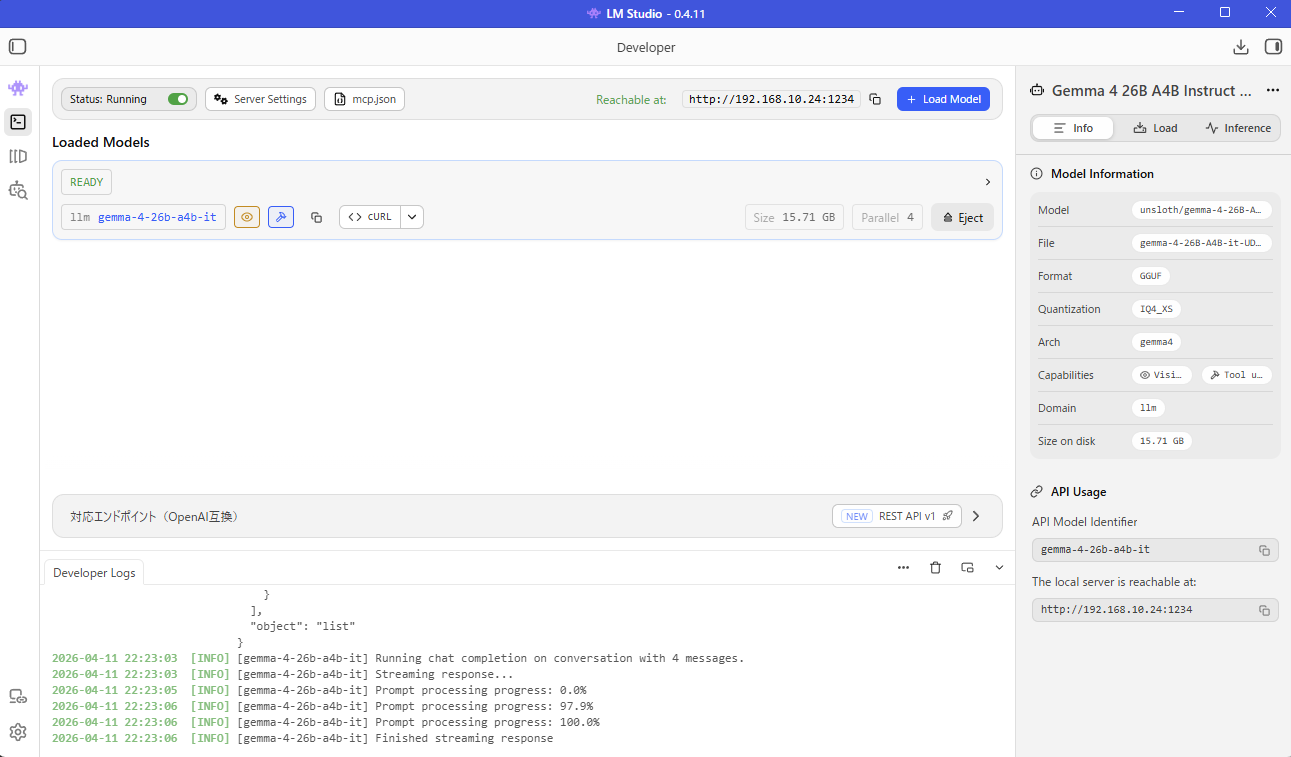
Developerタブを開き、好みのモデルを「Load Model」したら左上の「Status: Running」にチェックするだけ。
LM Studioのシステムプロンプトが使えれば良かったんだけど、SillyTavernに上書きされてしまうのでここでは設定せず。
Irodori-TTS
Windowsのターミナルを開いてまずはUVインストール。
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
一旦ターミナル閉じて開き直し、Irodori-TTSインストール。
git clone https://github.com/Aratako/Irodori-TTS.git cd Irodori-TTS uv sync
動作チェックは以下を実行。
uv run python gradio_app.py --server-name 127.0.0.1 --server-port 7860
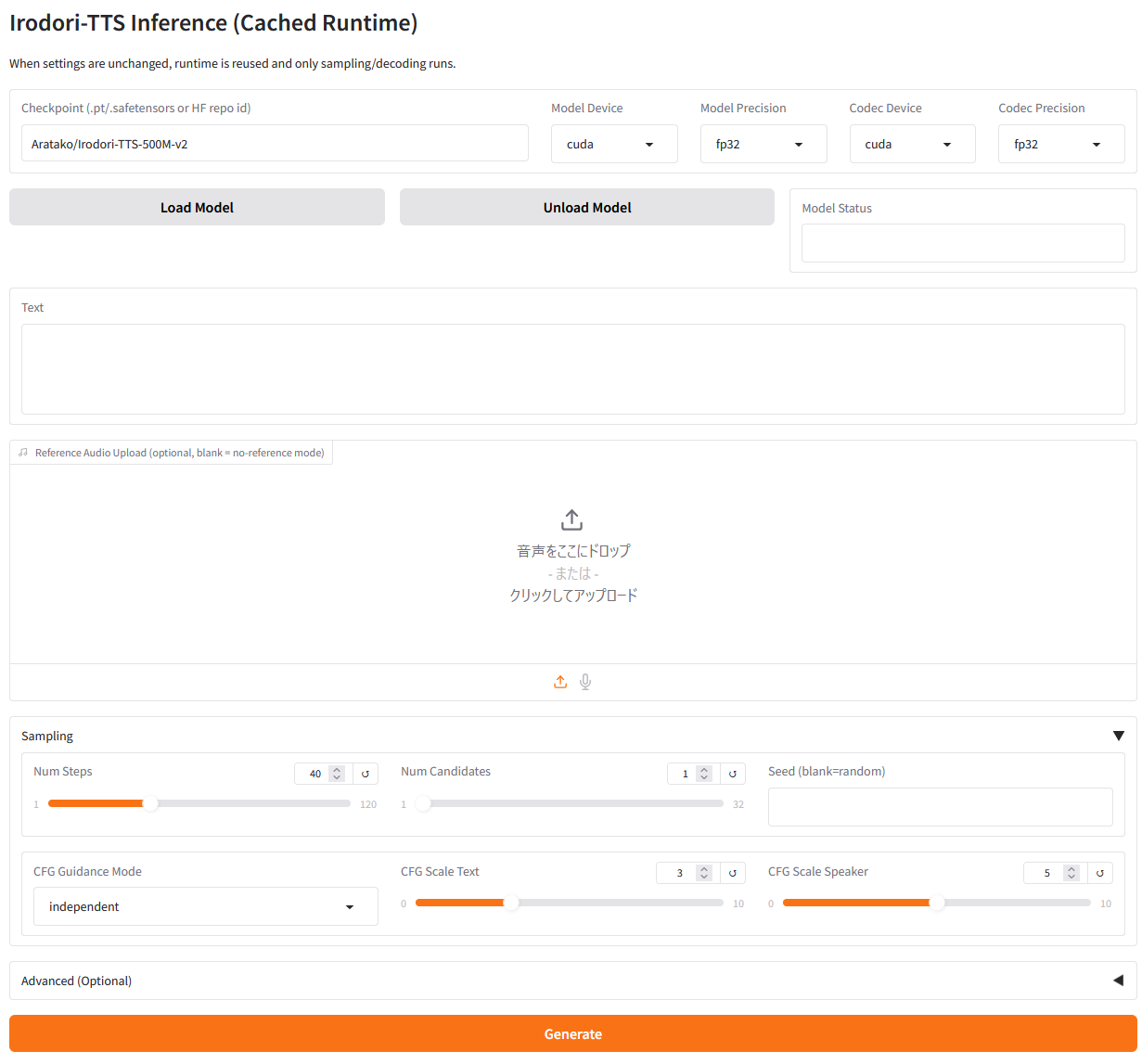 ブラウザでアクセスできるようになります。
ブラウザでアクセスできるようになります。
http://localhost:7860
「Load Model」してTextに文章入力、Generateボタンで生成できます。
好きに喋らせられるので、もうこれだけで楽しい。
Irodori-TTSはOpenAI APIに準拠してないので、準拠させるコードをAIに書かせました。
ファイル名は「bridge.py」で、Irodori-TTSフォルダに入れてください。
from fastapi import FastAPI, HTTPException
from fastapi.responses import FileResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import subprocess
import uuid
import os
import sys
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
OUTPUT_DIR = os.path.join(BASE_DIR, "outputs")
os.makedirs(OUTPUT_DIR, exist_ok=True)
class SpeechRequest(BaseModel):
model: str = "tts-1"
input: str
voice: str = "default"
@app.get("/")
def root():
return {"ok": True, "service": "irodori-tts-bridge"}
@app.get("/v1/models")
def models():
return {
"object": "list",
"data": [
{"id": "tts-1", "object": "model", "owned_by": "local"}
]
}
@app.post("/v1/audio/speech")
def speech(req: SpeechRequest):
filename = f"{uuid.uuid4()}.wav"
filepath = os.path.join(OUTPUT_DIR, filename)
try:
result = subprocess.run(
[
sys.executable, "infer.py",
"--hf-checkpoint", "Aratako/Irodori-TTS-500M-v2",
"--text", req.input,
"--no-ref",
"--output-wav", filepath
],
cwd=BASE_DIR,
capture_output=True,
text=True,
check=True
)
print("STDOUT:", result.stdout)
print("STDERR:", result.stderr)
except subprocess.CalledProcessError as e:
print("FAILED STDOUT:", e.stdout)
print("FAILED STDERR:", e.stderr)
raise HTTPException(
status_code=500,
detail={
"stdout": e.stdout,
"stderr": e.stderr,
"returncode": e.returncode
}
)
if not os.path.exists(filepath):
raise HTTPException(status_code=500, detail="wav file was not created")
return FileResponse(filepath, media_type="audio/wav", filename=filename)
APIの起動は以下です。
uv run python -m uvicorn bridge:app --host 127.0.0.1 --port 8001
SillyTavern
ターミナルからインストール。
git clone https://github.com/SillyTavern/SillyTavern-Launcher.git cd SillyTavern-Launcher start installer.bat
途中で質問されたら 1, y, y, 1 とそれぞれ回答。するとショートカットが2つ作られるので「SillyTavern」の方をダブルクリック。
起動したら以下からアクセス。
http://127.0.0.1:8000/
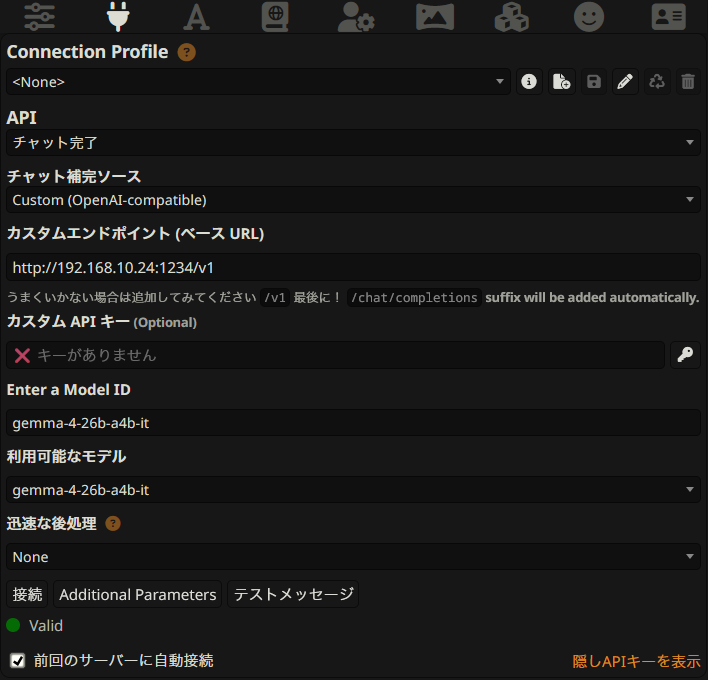 開いたら上部のAPI接続メニューから、画像のように記述します。
開いたら上部のAPI接続メニューから、画像のように記述します。
カスタムエンドポイントはLM Studioの「Reachable at:」のURLに /v1 を追加したものです。たまに別のURLになってることがあるので要確認。
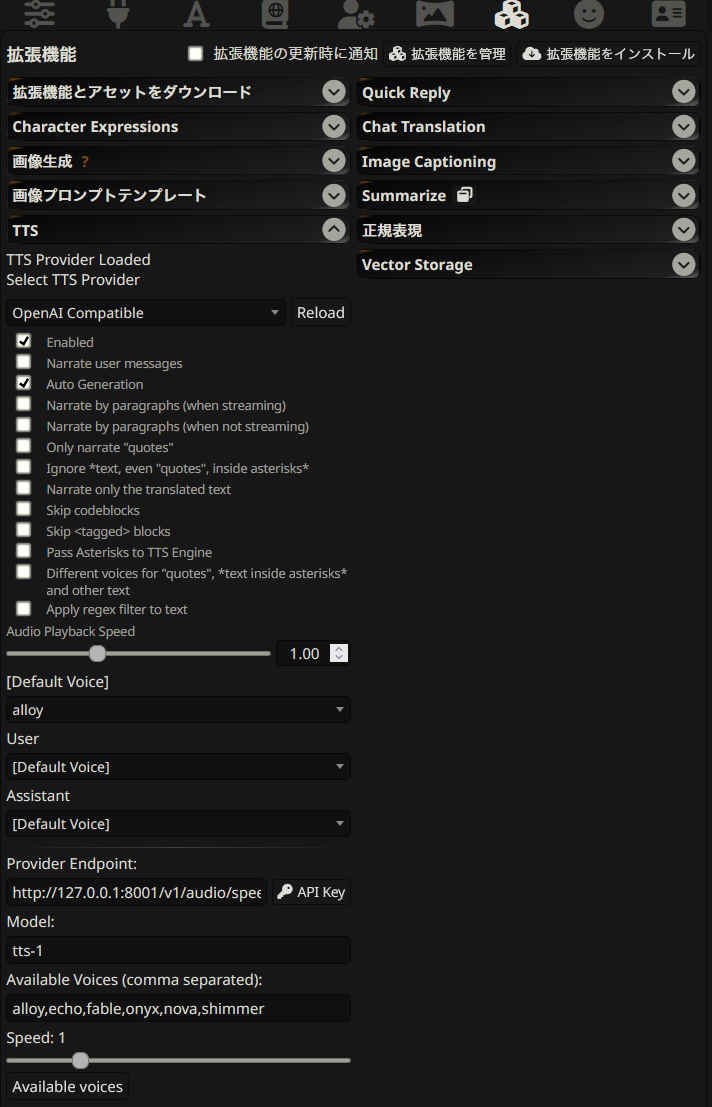 次は拡張機能メニュー。こちらのTTSから設定するんだけど、うまく接続しなくて苦労した。
次は拡張機能メニュー。こちらのTTSから設定するんだけど、うまく接続しなくて苦労した。
「Provider Endpoint」にはIrodori-TTS側で作成したAPIの
http://127.0.0.1:8001/v1/audio/speech
を記載します。
あとは上部のキャラクター管理メニューから、キャラの性格や画像を設定できます。
使用感
画面下のテキストフォームに入力すればテキストと音声で返事してくれます。今までテキストのみだったのが音声で返してくれるのは嬉しいね。
しかし音声で返事くるの20秒くらいかかる。結構長い。PC性能によるんだろうけど。
あとIrodori-TTSは長文だと日本語が破綻してしまう。仕方ないのでSillyTavernのシステムプロンプト(キャラの性格)に「最大80文字」と入れてます。
そんな感じで問題なく動くけど、80文字だと複雑なやり取りが出来ないのと、やはり待ち時間長いのがつらいなと思いました。
まとめ
苦労してやりたいことは実現できました。
楽しいけど重たいのがネックです。今後の進化に期待。


コメント